Creating a developer-friendly Kubernetes platform with GitOps

Written by Jos van Bakel on 4th August 2022
After the first masterclass of the Holodeck 101 event, it was time for me to take the stage and share our knowledge about GitOps. For all developers to be able to work with the Holodeck platform, we – the infra team – set up a template to make it easy for developers to create and deploy a new service by themselves without the interference of infra. In this article I’ll explain how we did this and were able to hide the complexity of Kubernetes for developers.
What is GitOps?
GitOps is like DevOps, but GitOps is used for infrastructure. This infrastructure is described entirely by configuration files. To compare the current state of the infrastructure to the desired state (like it is described in the configuration files), a tool is used. This tool performs a set of actions to align the desired and actual state. This is commonly called “infrastructure as code”, since the configuration files can be represented or generated by code.
The benefits of infrastructure as code
Why would you go through all this trouble to set up your infrastructure? Because infrastructure as code has a large number of benefits:
- Consistency: the real infrastructure can be checked — and aligned — with what has been written in code.
- Reproducible: it is very easy to replicate the infrastructure to another location.
- Scalability: as a result of being reproducible, scaling up can be easier (depending on the use case).
- Modular: best practices of coding can be applied, like using modules to abstract common patterns.
- Collaboration: multiple people can work together on a change (in code).
- Coding standards: syntax highlighting, formatting, linting, testing, code reviews, etc.
- Documentation: difficult parts of the infrastructure can be documented, with for example the reason for a choice, or explaining a difficult flow.
- CI/CD: changes can be tested in CI in a test environment, and CD can be used to auto deploy changes to the real environment.
Storing the code in a Git repository
GitOps is not just infrastructure as code. As the name implies, it also has something to do with Git. It may be trivial, but the idea is that the infrastructure of code is stored in a Git repository. This ensures that there is a history of changes to the infrastructure and provides a solid way to collaborate. More specifically, GitOps dictates that any change is made (deployed) by just making a git commit. The whole pipeline of testing, reviewing, etc. up until the final deploy must be automated with CI/CD. The idea is that the only point of entry to make changes to the infrastructure is Git.
What we mean with GitOps
In Holodeck we use the word GitOps not just to describe the workflow, as is described above, we use it to describe the entire Holodeck platform. The Holodeck platform is a platform-as-a-service (PaaS) built for developers-without-infrastructure/operations-knowledge in mind. We wanted to build a platform with modern technologies, without imposing the burden of learning all of these technologies on the users of the platform. We did this by not only leveraging GitOps for the infrastructure itself, but also for the services deployed on the platform.
One of the goals of Holodeck as a platform is to enable teams to do their own DevOps. Creating and deploying a new service on Holodeck requires little knowledge of the underlying technologies and — this is also important — requires zero interaction with the infra team. Other aspects of DevOps like monitoring, alerting, dashboarding, log inspection and more, are all automatically configured by the GitOps workflow, developers can access the tooling themselves. This empowers teams to own their service, from development to deployment to maintenance. It also reduces the workload on the infra team and partially removes them as a bottleneck, so development is not slowed down.
Overview of the Holodeck platform
The following picture gives a high level overview of the Holodeck platform:
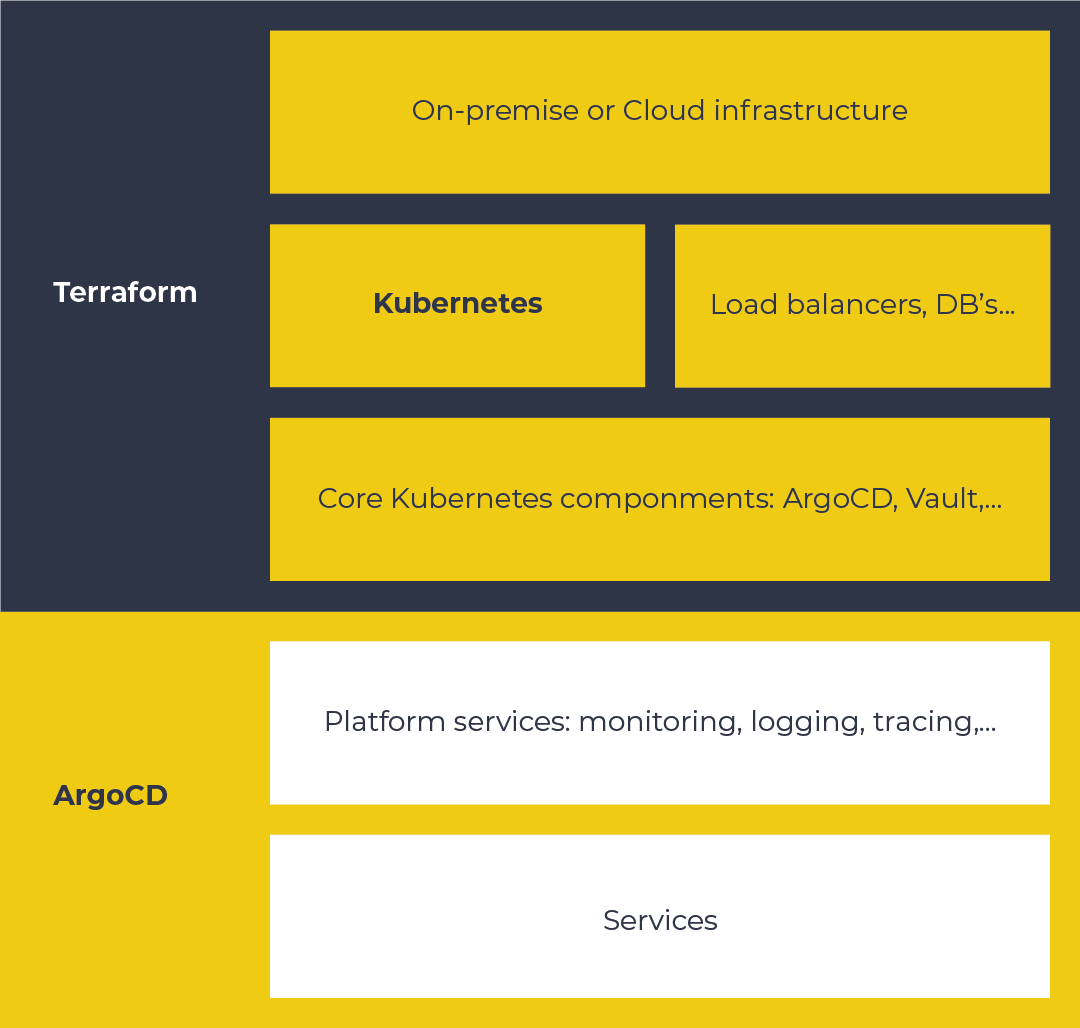
The base
The current platform is built on the AWS cloud. We tried to build the platform as cloud agnostic as possible, so we have the flexibility to switch to another cloud or even move the platform on-premise (which is eventually our goal).
Kubernetes is running on top of the cloud, or on-premise infrastructure. For now we are using AWS EKS. Besides Kubernetes, there are the necessary network components (load balancers) and optional databases that are not hosted on Kubernetes.
ArgoCD and Vault are provisioned on top of Kubernetes, and together with some plumbing (Ingress-NGINX, cert-manager, etc.), this forms the base platform. Terraform is used to provision and maintain the base, it can provision the infrastructure from scratch (except for a few manual actions, related to secrets and DNS). This allows us to quickly scale out to other regions, or in disaster scenarios, ditch and rebuild the entire infrastructure.
Platform services
ArgoCD — provisioned in the base layer — can now take over from Terraform in provisioning further platform services. A bit further on, I’ll explain what ArgoCD is, for now think of it as Terraform on Kubernetes.
In this layer, all additional platform services — which are not needed in bootstrapping — are provisioned. This includes, but is not limited to:
- Prometheus (monitoring)
- Grafana and Kiali (dashboarding)
- Istio (service mesh)
- Jaeger (tracing)
- Crossplane (managed databases outside Kubernetes)
- Nats (message bus)
- Vault (secrets)
For these services, provisioning with ArgoCD is preferred over Terraform for multiple reasons:
- The same GitOps flow is used for platform and enduser services
- The feedback cycle is much shorter
- ArgoCD has no Terraform state
- ArgoCD runs continuously
Making Kubernetes understandable
Kubernetes was built with a simple idea: you tell it what resources you want defined in YAML files, and Kubernetes will make sure the resources are actually there and stay there. A resource can be anything. Kubernetes is mainly built around container orchestration, thus the main resources are things in and around containers. However, Kubernetes is not limited to these resources. By defining Custom Resource Definitions (CRD’s) and deploying controllers, Kubernetes can be extended with almost any resource. Although the idea is simple, building things in Kubernetes can be complex. This is because you need domain knowledge to write the resources. And to make matters worse, the domain can be extended by CRD’s. We don’t want to impose this burden on developers.
Kubectl is the new ssh. Limit access and only use it for deployments when better tooling is not available. — Kelsey Hightower
Helm is a useful abstraction over Kubernetes YAML’s to make it modular and more DRY. The problem does however remain that you still need domain knowledge of Kubernetes resources. Helm code can also be really tricky to get right: making errors in YAML extended with Go templating is all too easy.
The solution we developed for this problem is: a holodeck-service Helm template (chart).
A Helm template for developers
All services developed on Holodeck use the holodeck-service Helm template. The template enables developers to set configuration variables (via environment variables), load in secrets (from Vault), request a database instance (via Crossplane), and much more. The only thing developers need to know are the available parameters in the Helm template. The template generates the necessary Kubernetes YAML for the service. Kubernetes complexity is hidden from the developer by the abstraction. Our infra team has knowledge of Kubernetes and various other infrastructure components. With this knowledge, they maintain and add features to the Helm template, making features available to developers via parameters.
global: domain: services service: python-example holodeck-service: secrets: enabled: true envVarsFromVault: WEATHER_API_KEY: WEATHER_API_KEY FASTSTREAM_CREDS: FASTSTREAM_CREDS envVars: SENTRY_DSN: value: "" WEATHER_BASE_URL: value: "<https://api.openweathermap.org>" ingress: rewrite: true postgres: enabled: true storage: 10 # GiB migrate: command: ["alembic", "upgrade", "head"] redis: enabled: true
helm/values.yaml
ArgoCD as the solution
Services can be deployed to Kubernetes with Helm. Specifically, we could call helm upgrade from the GitLab CI pipeline to deploy. We encountered a few problems with this approach:
- The CI needs credentials to Kubernetes and to our private Helm repository.
- Most deployments need to be done in several steps (ex. first deploy database, then perform the migrations, then deploy the new version of the application). Helm doesn’t support multi-stage deployments like this (at the time of writing).
- No overview of what version is running in each environment.
- Kubernetes access control is not great.
ArgoCD is a great tool that helped solve some of these problems, and more! ArgoCD is “Declarative GitOps for Kubernetes”. It monitors one or more Git repositories. On each commit, it will update resources in Kubernetes (via Helm or native YAML’s).
We set up ArgoCD to monitor a “single source of truth” repository, called services-root. The repository contains a JSON file per service, per environment. The JSON describes which git commit (and Docker image tag) of the service repository should be live in the environment. For example:
{
"cluster": "staging",
"service": "python-example",
"imageTag": "a2a7d76d9f6af65f96fd46cc92bcee7f065d8514",
"targetRevision": "a2a7d76d9f6af65f96fd46cc92bcee7f065d8514"
}
An ApplicationSet is configured to watch changes on the services-root repository. It will create an Application resource for each JSON file. The Application resource triggers ArgoCD to checkout a git commit of the repository, and apply the Helm chart to Kubernetes, resulting in the deployment of the service.
Ease in using the platform
We focused on making the platform easy to use for developers. Hiding the complexity of Kubernetes and a whole bunch of other tools needed to build a solid PaaS. During the masterclass I did a demo showing the steps a developer would need to take to create and deploy a new service. These steps are:
- Create a git repository on GitLab
- Clone the python-template with copier
- git commit && git push
- Staging is automatically deployed.
- Manually click on deploy-production in Gitlab.
Looking at the steps, I think we succeeded in our goal of enabling developers to use the platform without help from the infra team. What do you think of our solution? Let us know in the comments below!

Your thoughts
No comments so far