How to choose the best natural language understanding system

Written by Rik Huijzer on 12th February 2019
For the past six months, I have been working at Spindle on my thesis for the master Computer Science and Engineering at the Eindhoven University of Technology. The thesis contains two research questions on natural language understanding systems. In this article, I will elaborate on the first research question: Can an open-source benchmarking tool for NLU systems and services be created? The full thesis can be found on Github.
Natural language understanding
The scope of the thesis is chosen to be natural language understanding (NLU). NLU aims to understand text written by a user and is used in chatbots. This means that the systems have two practical constraints. The first is that the systems have to reply in real-time. Secondly, the systems should work after being trained on few training examples (about one hundred). Specifically, the thesis has focussed on intent classification and named-entity recognition (NER).
Intent classification and named-entity recognition
Intent classification aims to classify a sentence and guess the intent of the user. Named-entity recognition aims to classify subsentences to extract information like telephone number and location from the sentence. For example:
What is the weather in London tomorrow?
After doing intent classification and named-entity recognition the system would have extracted the following information.
What is the weather in [London](location) [tomorrow](date)?
GetWeather
The GetWeather intent can be used to start an action to determine the weather for the location London and the date tomorrow. My first research goal was to create a tool to benchmark various intent classification and NER systems. The rest of this article will explain why a benchmarking tool is relevant and how to choose the best system.
Various NLU systems
Currently, there are many NLU systems available. This is a non-exhaustive list:
- Rasa
- DeepPavlov
- Watson Assistant
- Google Dialogflow
- Amazon Lex
- Microsoft LUIS
- Wit.ai
- Deep Text
- Lexalytics
- Pat
- Kore.ai
Sixteen more are listed by Dale [1].
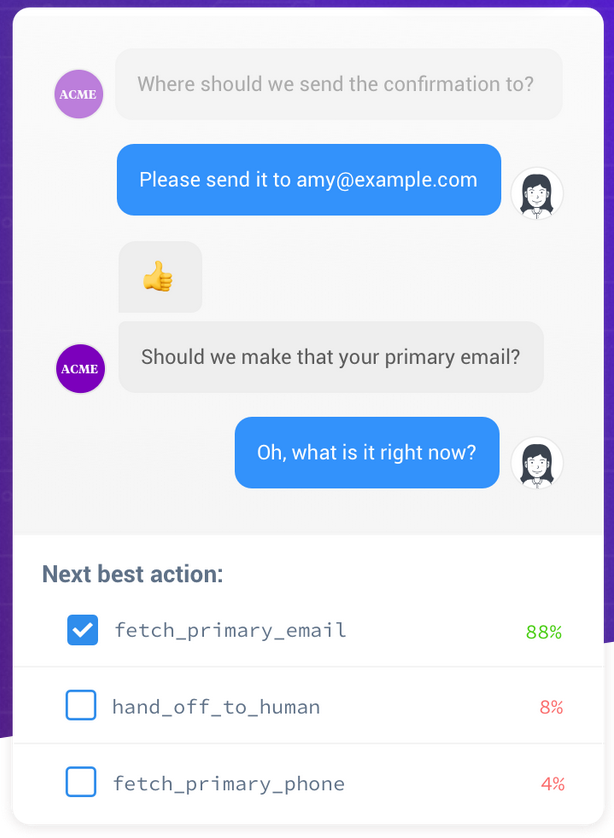
Rasa using intent classification in their chatbot
Accuracy seems like an obvious metric for choosing the best system. Nobody likes it when sentences are misinterpreted by a chatbot. Higher accuracy means that fewer sentences are misinterpreted. This is why various parties run benchmarks and use this to draw conclusions about the best performing system.
Benchmarking NLU systems
However, several issues can be pointed out which question the validity of these conclusions. Credits to Braun et al. [2] for publishing datasets and a methodology for benchmarking NLU systems. Their results were presented in 2017. It is very likely that one of the benchmarked systems has changed their classifier since then. Unfortunately, they did not provide code to reproduce the benchmark.
Also in 2017, Snips has benchmarked their own system against competitors and claim to outperform all competitors. Although the Snips benchmark is quite transparent, it does not prove that they did not (accidentally) cherry-pick the dataset. The authors of a system named DeepPavlov show [3] that they also outperform all other systems. This is done by using a system trained on a related dataset (transfer learning). This suggests that the system does not generalize well. Finally, Botfuel claims to also have the highest accuracy. The accuracies reported for the other systems are taken from the scores reported by Braun et al. This is an advantage for the (newer) Botfuel scores.
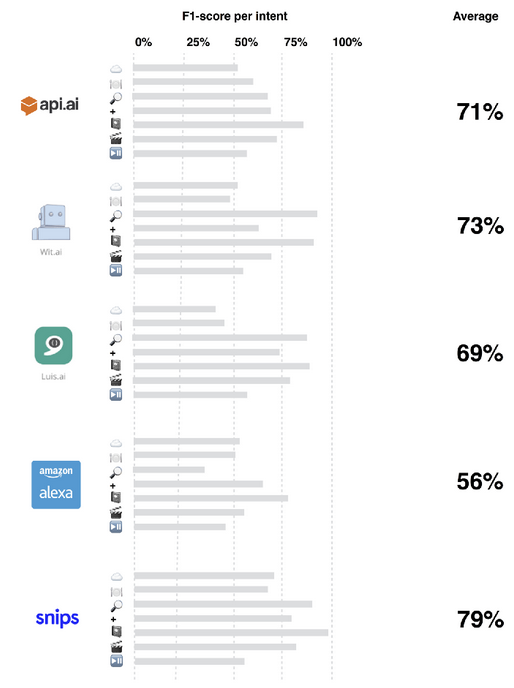
Snips showing how they have outperformed all competitors
Creating my own benchmarking tool
In an attempt to be more independent, I created a benchmarking tool called bench. It is far from finished, but some general conclusions are clear. One conclusion is that choosing based on only accuracy is not a good idea. The NLU field is rapidly changing. To show this, we take a look at the current state of the art (SOTA) for named-entity recognition.
This Github page has a nice summary for the CONLL03 NER dataset. I will copy it here and use company names since they are easier to remember:
- Zalando. F1 score: 0.931. Date: 24 June 2018
- Google. F1 score: 0.928. Date: 31 October 2018
- Stanford / Google Brain. F1 score: 0.926. Date: 22 September 2018
From this list, we can infer that a new SOTA accuracy score is obtained every few months. So the ‘most accurate’ system has to also update every few months.
Performance indicators
The performance of your data also depends on the following:
- Used algorithm. It could be that Google has published SOTA research, but not implemented it in Google Dialogflow. The only way to figure it out for sure is to continually test all systems.
- Training data size. Although bigger is better, some algorithms can handle few examples (few-shot learning) better.
- Domain. An algorithm could be better suitable for handling formal governmental text instead of less formal Wikipedia text.
- Data language. Since most research is focused on showing SOTA on public data sets, they are often optimized for English. How they perform on other languages might differ.
Conclusion
All in all, it is better to pick a system which seems easy to implement for you and seems to have reasonable accuracy. Choosing a system based on accuracy is non-trivial and requires to switch systems often. In my thesis you can read all about my benchmark. It also contains an answer to the question of whether we can improve classification accuracy for NLU. Let me know your thoughts on the subject in the comments below!
[1] Robert Dale. Text analytics APIs, part 2: The smaller players. Natural Language Engineering, 24(5):797-803, 2018.
[2] Daniel Braun, Adrian Hernandez-Mendez, Florian Matthes, and Manfred Langen. Evaluating natural language understanding services for conversational question answering systems. In Proceedings of the 18th Annual SIGdial Meeting on Discourse and Dialogue, pages 174-185, 2017.
[3] Mikhail Burtsev, Alexander Seliverstov, Rafael Airapetyan, Mikhail Arkhipov, Dilyara Baymurzina, Nickolay Bushkov, Olga Gureenkova, Taras Khakhulin, Yuri Kuratov, Denis Kuznetsov, et al. DeepPavlov: Open-source library for dialogue systems. Proceedings of ACL 2018, System Demonstrations, pages 122-127, 2018.

Your thoughts
No comments so far